
[Note: This was originally posted to my blog 7/10/09]
Just to be clear, this is not an abstract example. While I employ this methodology for a number of communities and topics, the one I will use as an illustration here is what is generally referred to as “Government 2.0”. Also, you may notice that this is in some respects similar to the popular post I penned earlier: How I use Twitter to be a Better Public Servant. This post focuses more closely on my methodology, which I have since refined.
Problem: Signal-to-Noise
For the uninitiated, signal–to-noise ratio is essentially the level of a desired signal (in this case valuable information) to the level of background noise (valueless or value-neutral information).
When discussing social media, I often run into people who look at it and see a whole lot of content varying in usability and wonder how in the hell they are going to manage it without getting overwhelmed. In short, their question is: how do you get to what you want and filter out what you don’t?
Solution: What You’ll Need
My methodology for filtering out the noise relies on two things:
- An active community creating, linking, rating, responding, sharing and tagging content; and
- Knowing what tag(s) is/are being used by that community.
It also requires 5 tools, all of which allow me to manipulate and/or read RSS feeds. They are:
I will try to keep this explanation as clear possible and supplement it with supporting graphics whenever possible. But before I get into the technical explanation, I want to share this little hand drawn process map that will hopefully pique your interest, simplify the model, and illustrate how I start with approximately 250 items of unknown importance (re: Government 2.0) and whittle them down to 3 items over a single day.
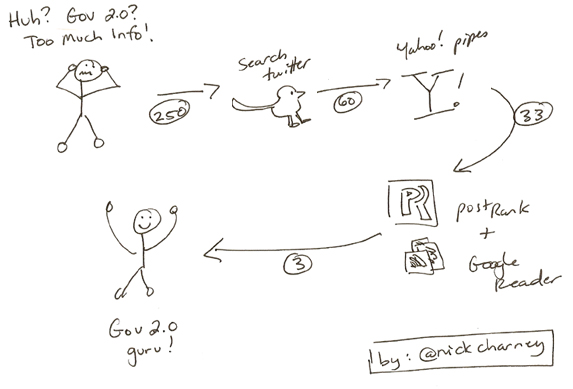
Step 1 (Install Firefox, PostRank extension and set up a Google Reader Account)
If you don’t already use Firefox, then you will need to install it for this to work. [Hint: here is a valid reason to get it installed at work.] You will also need to install the PostRank add-on for Google Reader. Then either sign in to your existing Google account or create one.
Step 2 (Search Twitter)
Now you will need to use search.twitter.com to create your initial RSS feeds.
Benefits of searching Twitter:
- Results are real time (i.e. what people are talking about right now);
- You don’t need a twitter account to do it; and
- You only need to set up your search once and then grab the RSS feed from it.
In order to set up your searches, click the advanced search option on the main page, and configure your search as follows:
- Must contain “#gov20” (no quotes) [Hashtag denotes that content is relevant to Government 2.0];
- Must contain a link [I want the full article, not a 140 character tweet about the article]; and
- Must contain either “RT” or “via” (no quotes) [Syntax for retweeting, a social measure of value which indicates that someone has decided to re-disseminate that link within their own network].
This search is configured to capture only links being retweeted (RT or via) on twitter about Government 2.0 (#gov20). Therefore, this first step removes any of the chatter that doesn’t contain links and any content that hasn’t been deemed worthy of re-disseminating by people on Twitter.
However, within the wider Government 2.0 community, there are multiple hashtags being used, including :
- #opengov
- #opendata
- #govloop
- #gov20
So if you want to capture everything within that community, then you are forced to repeat the process, substituting the hashtag [Note: it is possible to set this up as a single feed, but separate feeds are more manageable.].
Step 3 (Yahoo Pipes)
Yahoo Pipes is a free web-based program that allows users to manipulate RSS feeds and re-syndicate them afterwards. It can be overwhelming at first, and I am still by no means an expert, but I am achieving my desired results using it.
I start by importing the four RSS feeds from the searches we ran in Step 1. Yahoo Pipes combines all four feeds into a single feed. If you look at that feed closely you will see that there is some duplication. This duplication occurs when people tag content with two (or more) of the hashtags I searched for and when a tweet is retweeted multiple times by different users. In order to deal with the duplication I have configured Yahoo Pipes to analyze the content of each feed item. I then apply a filter that removes any non-unique item from the feed based on the results of that analysis.
An important caveat is that Yahoo Pipes removes the duplicates in order of occurrence, which means that if the content analysis module determines that something has been retweeted 5 times, it keeps the original retweet while removing the others. The importance of this will become apparent later when we discuss the application of PostRank filters.
Here are a couple of screenshots of the Government 2.0 pipe I am running. The first shows the starting point of the pipe prior to applying the filter. As you can see it indicates 60 items in the feed (look bottom right).

Here is the second screenshot which indicates that after we apply the filter. The pipe is down to 33 items (again, bottom right).
 Step 4 (Google Reader and PostRank)
Step 4 (Google Reader and PostRank)
Now that you are rolling with Firefox, login to Google Reader and add the feed you created in Yahoo Pipes.
Now if you look near the top of the page you will see a drop down filter option that allows you to filter the content within your reader using Post Rank (the add-on you installed earlier).
PostRank allows you to filter items by the community’s level of engagement with the content: it measures other content being created as a response to this content (e.g. blog posts, comments, retweets, clicks, etc). In short, it gives you a social measure of the popularity of each item in the feed based solely on how and how often people are interacting with the content itself. This is why the Yahoo Pipes filtering process is important, keeping the first retweets (chronologically) allows PostRank to give an accurate measure of the susequent retweets, click throughs, etc.
[Note: This is an awesome extension that can do a lot more for you then just this. I use PostRank daily to determine which posts I should read and which I can probably skip. (More details can be found here).]
Finally here is a screenshot showing the application of the “Best” setting to my original feed in Google Reader.

Notice anything interesting? There are only 3 items there. This process started out with approximately 250 items of unknown importance ended with 3 items of high importance, which is clearly much more manageable than 250, especially when we remember that we are talking per day here.
Three Usual Objections
Despite showing how effective the filter is in terms of whittling down the number of items I have to decide to read or not (because yes, even with all this I still decide whether or not to read them), people remain skeptical.
Three questions frequently come up whenever I explain it:
Q1: What if you miss something?
A1: Fair question, but no one is catching everything no matter what their methodology. Besides, where am I more likely to miss something? At the beginning when I am dealing with approximately 250 items, or at the end when I am dealing with 3?
Q2: How can you be sure what you are reading is important?
A2: Because the methodology is designed to deliver what people in the community are reading and reacting to; the fact that they are reading and reacting to it is what makes it significant. In other words, if it isn’t being read already, then I would argue that it probably isn’t required reading.
Q3: Can you give a concrete example of something you found that was of value that you might not have found otherwise?
A3: This example is from the field of knowledge management where I employ the same methodology, but I cite it because it was the best find to date. I came across a knowledge management conference in Copenhagen, which I would otherwise have never known to look for. The best part about that conference was that they made all 250 of the discussion papers presented at the conference available on their website. I skimmed the abstracts and downloaded all of the papers that discussed the confluence of information communications technologies, knowledge management, and communities of practice. I walked away with over 25 papers that were either already peer reviewed, or in the process of. You want to talk about a learning opportunity?
Conclusion
I apologize if this was a little too technical. I tried my best to keep it simple and in plain language. Like I said, a lot of people have been asking me details about this so I figured this was the best venue to share it. I think it does a good job articulating how you can use social media to do research, which is not often the focus of social media discussions within government.
If you have any questions about or suggestions on how to improve, my methodology please let me know: I’d be happy to elaborate if required, and am always looking for better ways to improve my signal to noise ratio.
Cheers,


Loved this the first time I read it 🙂 Thanks for sharing, Nick!
Hey Nicolas,
Do you know of common hashtags used for public health or someone who can identify those for me? We’re just getting started using Twitter here at the county health department. Thanks — your post was really useful!
-Heather Heater
Portland ,OR USA
@Heather – Sorry I don’t know any off the top of my head, try searching twitter for related words, or looking at services like WeFollow
Heather,
If you’re looking to get into the health discussions, I receommend @edbennett and @lostonroute66 – excellent gentlemen and very connected.
I hope this helps.
And Nick – as always – a great post!! Still waiting for my one-on-one!
@mjmclean